defconsum(self) -> str: result = "" result += "HTTP/1.1 {status_code} {msg}\r\n".format( status_code=self.status_code, msg=status_code_dict[self.status_code]) result += "Content-Type: {type}\r\n".format( type = self.content_type) result += "Content-Length: {length}\r\n".format( length=self.length) result += "\r\n" result += self.reply return result
这样就可以更简单的编写视图函数
1 2 3 4 5
@http_api defhtml_test(http_request): data = "<html><body><h1>Hello, world!</h1></body></html>" result = Response(reply=data,type="html") return result.consum().encode()
defconsum(self) -> bytes: result = "" result += "HTTP/1.1 {status_code} {msg}\r\n".format( status_code=self.status_code, msg=status_code_dict[self.status_code]) result += "Content-Type: {type}\r\n".format( type = self.content_type) result += "Content-Length: {length}\r\n".format( length=self.length) result += "\r\n"
result = result.encode() iftype(self.reply) == bytes: result += self.reply else: result += self.reply.encode() return result
这样就能直接访问各种文件了,方便下一步渲染
1 2 3 4 5 6 7
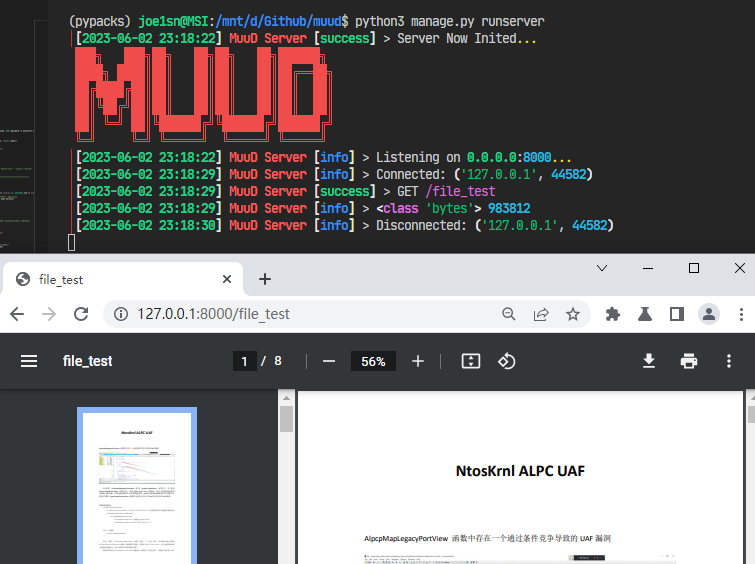
@http_api deffile_test(http_request): result="" withopen(r"/mnt/d/Github/muud/test/test.pdf","rb") as f: result = f.read() result = Response(reply=result,type="pdf") return result.consum()
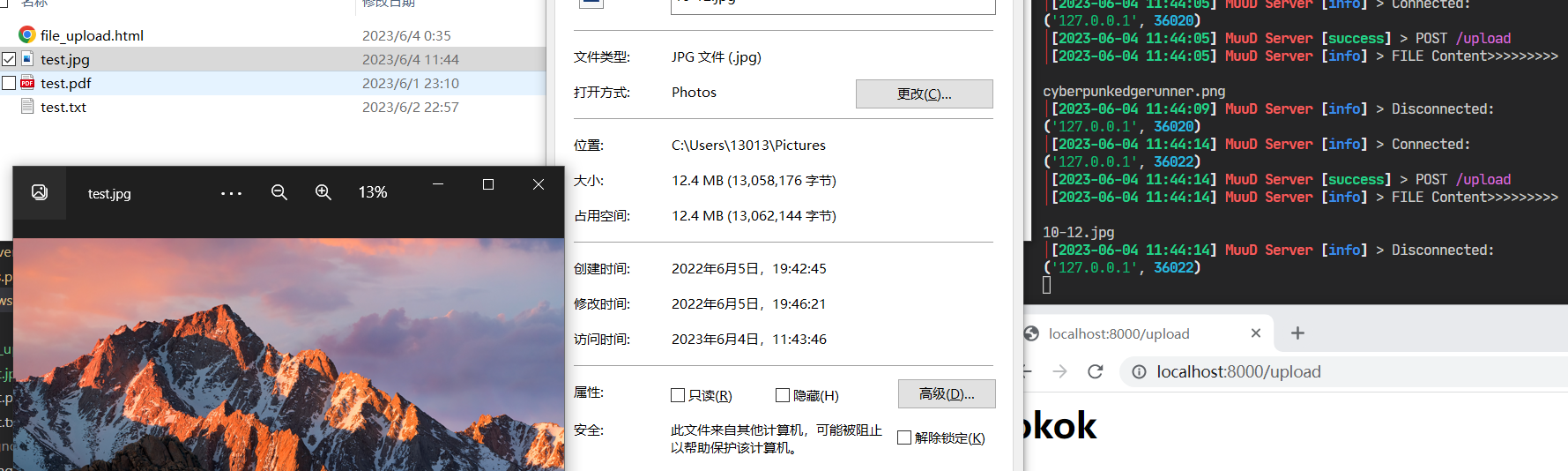
@http_api deffile_upload(http_request): result="" withopen(r"/mnt/d/Github/muud/test/file_upload.html","rb") as f: result = f.read() result = Response(reply=result,type="html") return result.consum()
@http_api defupload(http_request): result="" info("FILE Content>>>>>>>>>") # info(http_request.data["len"]/1024,"KB") name = http_request.data["filename"] # print(http_request.data["file"][:0x20]) withopen(r"/mnt/d/Github/muud/test/"+name,"wb") as f: result = f.write(http_request.data["file"]) data = "<html><body><h1>okok</h1></body></html>" result = Response(reply=data,type="html",status_code=200) return result.consum()
elif event & select.EPOLLIN: # 有数据可读 try: data = b"" data = connections[fileno].recv(1024*1024*10) # print("data from server\n",data) if data: requests[fileno] += data
defconsum(self) -> bytes: result = "" if self.status_code == 302: result += "HTTP/1.1 {status_code} {msg}\r\nLocation: {location}\r\n\r\n".format( status_code=self.status_code, msg=status_code_dict[self.status_code], location=self.reply) else: result += "HTTP/1.1 {status_code} {msg}\r\n".format( status_code=self.status_code, msg=status_code_dict[self.status_code]) result += "Content-Type: {type}\r\n".format( type = self.content_type) result += "Content-Length: {length}\r\n".format( length=self.length) result += "\r\n"
result = result.encode() if self.status_code == 302: pass else: iftype(self.reply) == bytes: result += self.reply else: result += self.reply.encode() return result
之后可以在utils里面打包这些方法,我这里放在http_response下面
1 2 3 4 5
# 重定向 defredirect(http_url): data= str(http_url) result = Response(reply=data,type="text",status_code=302) return result.consum()