公众号:https://mp.weixin.qq.com/s/VsGaZ7LqFkziJRpxp0rEBQ
很经典一篇同时具有实践价值和学术研究价值的文章,原文名称:Meltdown: Reading Kernel Memory from User Space [1]。提前预告:由于没有找到合适的CPU所以复现是失败的
或许我们的公众号会有更多你感兴趣的内容

[复现]CPU Meltdown 漏洞与论文

很经典一篇同时具有实践价值和学术研究价值的文章,原文名称:Meltdown: Reading Kernel Memory from User Space [1]。提前预告:由于没有找到合适的CPU所以复现是失败的
摘要
写过论文都知道这部分就是对文章大概的描述,很关键的是这句
“Meltdown exploits side effects of out-of-order execution on modern processors to read arbitrary kernel-memory locations including personal data and passwords.”
Meltdown利用现代处理器乱序执行的副作用来读取包括个人数据和密码在内的任意内核内存位置。
The attack is independent of the operating system, and it does not rely on any software vulnerabilities.
该攻击与操作系统无关,不依赖于任何软件漏洞。
介绍
这部分首先简单讲述了计算机系统中的用户态内存和内核内存的分离机制,根据Intel的手册来说是 多层页表映射结构体中的U/S位决定的。还有从内核到用户的内存映射机制
Operating systems ensure that user programs cannot access each other’s memory or kernel memory. This isolation is a cornerstone of our computing environments and allows running multiple applications at the same time on personal devices or executing processes of multiple users on a single machine in the cloud.
操作系统保证用户程序不能访问彼此的内存或内核内存。这种隔离是我们计算环境的基石,允许在个人设备上同时运行多个应用程序,或者在云中的一台机器上运行多个用户的执行过程。
This hardware feature allows operating systems to map the kernel into the address space of every process and to have very efficient transitions from the user process to the kernel,
这种硬件特性允许操作系统将内核映射到每个进程的地址空间,并且从用户进程到内核有非常高效的转换。
接着描述了影响
Instead, Meltdown exploits side-channel information available on most modern processors
相反,Meltdown利用了在大多数现代处理器上可用的侧信道信息。
接着引出罪魁祸首
The root cause of the simplicity and strength of Meltdown are side effects caused by out-of-order execution. Out-of-order execution is an important performance feature of today’s processors in order to overcome latencies of busy execution units, e.g., a memory fetch unit needs to wait for data arrival from memory.
Meltdown的简单性和强大性的根本原因是乱序执行导致的副作用。乱序执行是当今处理器的一个重要性能特征,为了克服繁忙执行单元的延迟,例如,一个内存获取单元需要等待来自内存的数据到达。
可能没有了解过计算机组成原理的人认为我们的CPU是按照顺序去一行一行执行代码的,但事实并非如此。CPU为了加快运算并且避免长时间的等待,比如当CPU面临一个if分支的情况时,他会预测走向哪条分支,然后提前运行代码,这样当if条件判断结束后就不用再执行这部分代码了。不过分支预测错误就会造成性能损耗,因为CPU可能会执行错误的分支,然后再执行正确的分支,这个就是错误惩罚。这里我第一次是从《深入理解计算机系统》(CSAPP)这本书中认识的,这一段便于我们理解后续的漏洞。

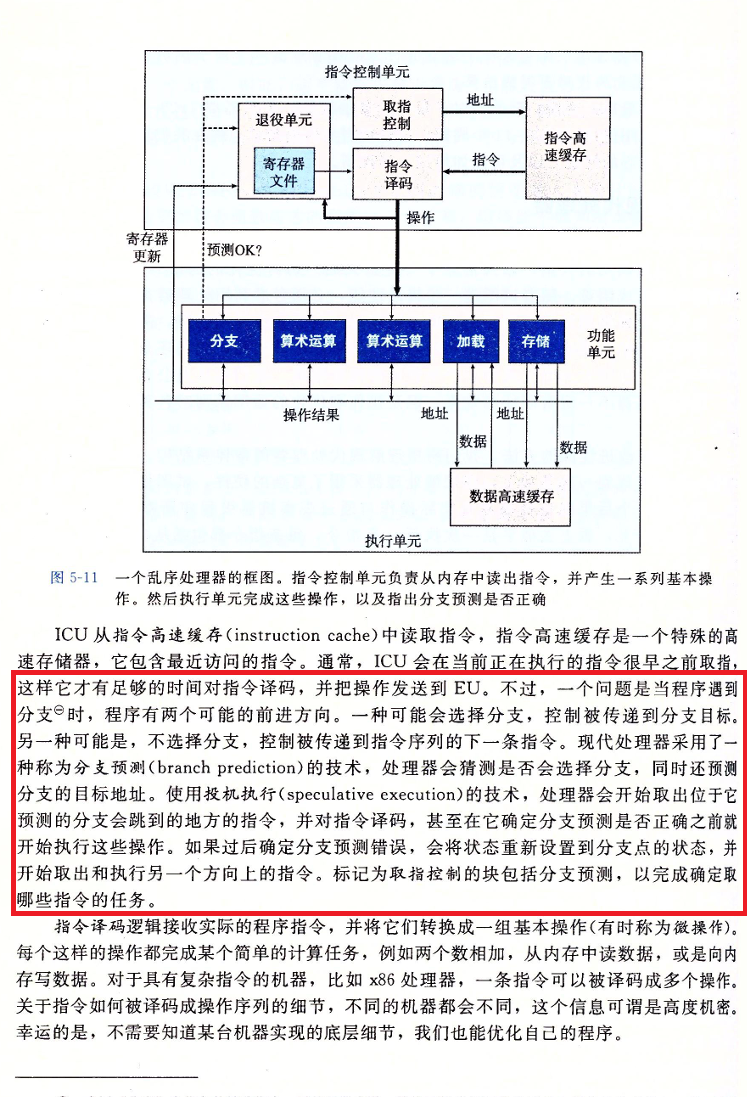
接着点明
one observation is particularly significant: vulnerable out-of-order CPUs allow an unprivileged process to load data from a privileged (kernel or physical) address into a temporary CPU register.
一个特别重要的观察是:易受攻击的乱序CPU允许非特权进程将数据从特权的(内核或物理)地址加载到临时的CPU寄存器中。
为什么呢?因为在分支预测中,CPU会将操作完成后的结果放入缓存(Cache)中,他不管数据来自哪里、有什么权限,只是操作系统会限制我们进行读写。
然后提到了对于利用比较重要的例子:刷新后重载。这个会在我们的后文中进行一个小例子的实验。
As a result, an attacker can dump the entire kernel memory by reading privileged memory in an out-of-order execution stream, and transmit the data from this elusive state via a microarchitectural covert channel (e.g., Flush+Reload)
因此,攻击者可以通过读取乱序执行流中的特权内存来转储整个内核内存,并通过微体系结构隐蔽通道(例如 刷新+重载 )从这种难以捉摸的状态中传输数据。
背景
首先讲了乱序执行,举了 Intel SkyLake 架构的示例
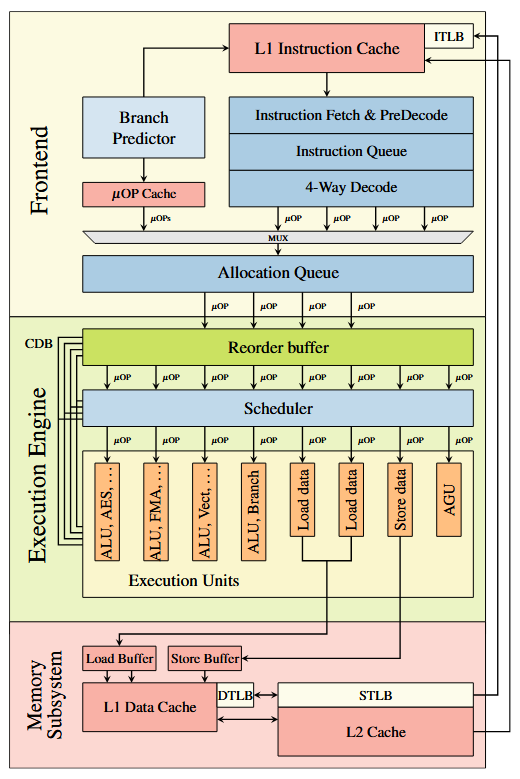
Figure 1: Simplified illustration of a single core of the Intel’s Skylake microarchitecture. Instructions are decoded into μOPs and executed out-of-order in the execution engine by individual execution units.
图1为英特尔Skylake微体系结构单个内核的简化示意图。指令被解码为μOPs,并由各个执行单元在执行引擎中乱序执行。
然后比较详细的讲述了内存映射机制和针对缓存的攻击,基本就是导读中的详细讲述。
一般程序中用户态的内存映射到低地址(0x0~0x7FFFFFFFFFFF),内核则处于高地址,这样进行系统调用的时候就不会切换页表,CPU缓存也不会失效。
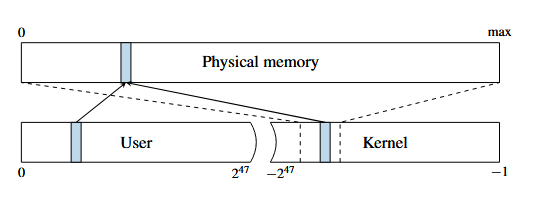
Figure 2: The physical memory is directly mapped in the kernel at a certain offset. A physical address (blue) which is mapped accessible to the user space is also mapped in the kernel space through the direct mapping.
图2:物理内存以一定的偏移量直接映射在内核中。一个映射到用户空间可访问的物理地址(蓝色)也通过直接映射映射到内核空间。
玩具化的例子
主要还是 Flush+Reload 方法。这里开始上我们的代码
论文中使用的是一个异常捕获的例子
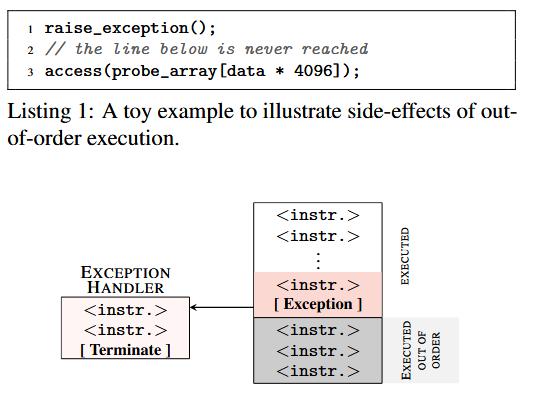
这里有一个简短的代码[3]
1 |
|
首先定义了一块 probeArray 缓存,每一行多出的 4096 是为了让CPU可以充分缓存其他值
使用_mm_clflush刷新缓存,让缓存失效
接着
1 | __try |
空指针引用可能会让缓存失效,但是CPU乱序执行仍然可能执行到probeArray[*p][0]++;。*p指向的是secret地址,然后再数组访问中还原成了secret的值,也就是让probeArray的第secret行的首个uint8值加一。
CPU意识到这一行不应被执行时,会让probeArray中的数据恢复,但是缓存依旧存在!接着我们记录读取probeArray中保存的数据的时间,但是第secret行的缓存存在,所以理论上他会比其他的缓存访问更快。
**注意:**这里仅适用于2018年前生产CPU,比如我在Ryzen9+win11上就无法测出
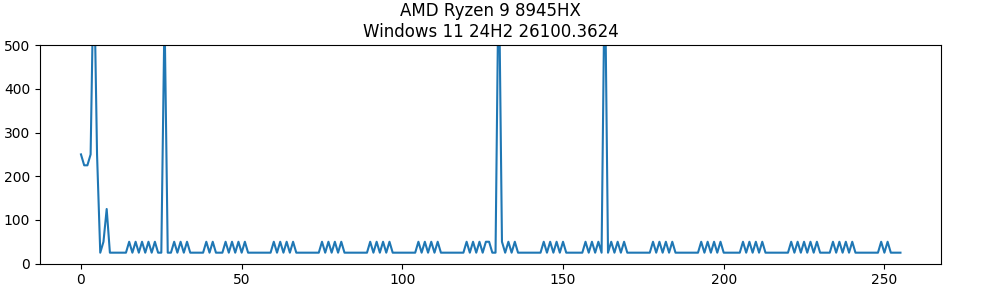
但是在我的老i5 虚拟机+物理机就可以
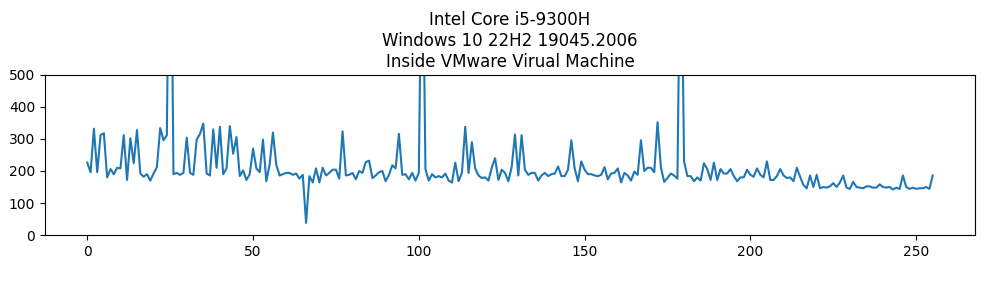
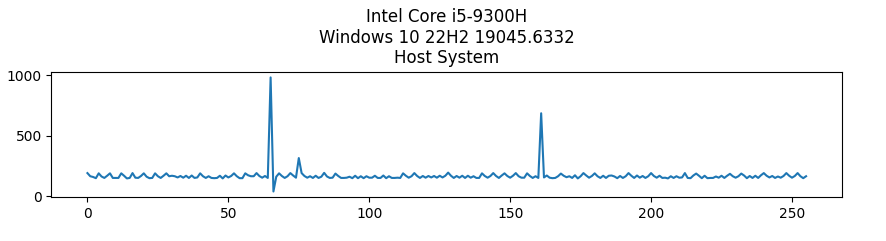
这里可以看到访问第66块内存的时间是最少的,这也符合论文中的结论

图4:即使一个内存位置只在乱序执行时被访问,它仍然被缓存。在256页的探测数组上迭代显示一个缓存命中,恰好在乱序执行期间访问的页面上。
如果我们把P指针换做内核态的地址那就很有可能读取到内核内存了,这也是meltdown中将CPU微指令架构转为为可观察的一个技巧
Meltdown
编写测试用例
首先假设我们有这样一块内核驱动,来源是[3]:https://github.com/dulong-lab/video-virtual-memory-materials
1 | NTSTATUS |
申请了一开NonPagePool然后将机密的值Secret复制给他。为了方便攻击的进行,开启了一个内核线程
1 | VOID |
KeSetSystemAffinityThread(1);这段代码跑在第一块核心上,理论上可以使用到一级缓存,并且循环访问secret数据,这有利于我们的攻击
最后就是关闭线程并卸载驱动
1 | VOID |
编写PoC
1 | int main(int argc, char *argv[]) |
SetProcessAffinityMask:让程序运行在第一个核心上- 重复运行
Steal函数 - 打印窃取的数据
1 | uint8_t |
接收内核地址作为参数。主要结构仍然是之前提到的Flush+Reload,但是使用了OutOfOrderExecution这段汇编,关于这段汇编的原文如下:

Listing 2: The core of Meltdown. An inaccessible kernel address is moved to a register, raising an exception. Subsequent instructions are executed out of order before the exception is raised, leaking the data from the kernel address through the indirect memory access.
清单2:熔断的核心。不可访问的内核地址被移动到寄存器中,从而产生异常。后续指令在异常发生前乱序执行,通过间接访存的方式将数据从内核地址泄露。
这里为了适配windows,编写一段差不多的
1 | void OutOfOrderExecution(void *target, void *probe_array, void *null); |
按照x64的传参顺序:target=rcx probe_array=rdx null=r8
1 | .code |
这里可以尝试不同的汇编组合,虽然最后我复现失败了,如果可行的话测试结果如下[2]:
后续章节
主要讨论了meltdown的性能、arm和AMD处理器上的差异、缓解措施例如KAISER和结论。
附录中展示了如何在实战环境中利用Meltdown
引用
[1] M. Lipp等, 《Meltdown: reading kernel memory from user space》, Commun. ACM, 卷 63, 期 6, 页 46~56, 5月 2020, doi: 10.1145/3357033.
[1] 合集·关于编写 x64 Windows 10 驱动以了解虚拟内存这件事 杜龙实验室 https://www.bilibili.com/video/BV1qV4y1T7Gz
[2] video-virtual-memory-materials dulong-lab https://github.com/dulong-lab/video-virtual-memory-materials