翻译-Scoop the Windows 10 pool!
公众号:https://mp.weixin.qq.com/s/ikuiJNzbCf532qzPVqZ1YA
或许我们的公众号会有更多你感兴趣的内容

原文:SSTIC2020-Article-pool_overflow_exploitation_since_windows_10_19h1-bayet_fariello
[toc]
Scoop the Windows 10 pool!
摘要:堆溢出是应用程序中一种相当常见的漏洞。利用此类漏洞往往需要对用于管理堆的底层机制有深入的理解。Windows 10 近期更改了其在内核空间中管理堆的方式。本文旨在介绍 Windows NT 内核中堆管理机制的最新演进,并展示针对内核池(Kernel Pool)的全新漏洞利用技术。
1. 引言
在 Windows 系统中,“池”(Pool)是指为内核空间预留的堆内存区域。多年来,内核空间的池分配器一直具有高度的特殊性,且与用户空间的分配器截然不同。然而,自 2019 年 3 月发布的 Windows 10 19H1 更新以来,这一状况发生了改变。用户空间中那个广为人知且已有详尽文档记录的“分段堆”(Segment Heap)7 被引入到了内核空间。尽管如此,内核中所实现的分段堆分配器与用户空间的版本之间仍存在某些差异,因为内核空间依然存在一些特定的资源与需求。本文将从漏洞利用(Exploitation)的视角出发,重点探讨内核分段堆中那些独有的内部机制。本文所呈现的研究内容专门针对 x64 架构。针对其他不同架构所需的适配与调整,本文暂未进行深入探究。在简要回顾了内核池分配器的历史演变及内部机制之后,本文将详细阐述分段堆在内核中的具体实现方式,以及它对内核池特有资源所产生的影响。随后,本文将介绍一种针对内核池内部机制的新型攻击手段,该攻击可用于利用内核池中的堆溢出漏洞。最后,本文将展示一种通用的漏洞利用技术:该技术仅需极小且可控的堆溢出条件,即可实现本地权限提升,将权限层级从“低完整性”(Low Integrity)提升至“SYSTEM”级别。
1.1 内存池内部机制
本文将不深入探讨内存池分配器的内部细节,因为这一主题此前已在诸多文献中得到广泛阐述 [5];不过,为了确保读者能对本文内容有全面的理解,在此仍需简要回顾一些关键的内部机制。本节将介绍 Windows 7 系统中内存池的一些内部结构,以及过去几年间针对内存池所引入的各类缓解措施与改进。此处所阐述的内部机制将重点聚焦于那些恰好容纳在单个内存页(page)内的内存块(chunk),因为这类分配是内核中最常见的内存分配类型。至于大小超过 0xFE0 字节的内存分配,其行为模式有所不同,因此不在本文的探讨范围之内。
内存池分配:Windows 内核中用于分配和释放内存的主要函数,分别是 ExAllocatePoolWithTag 和 ExFreePoolWithTag。
PVOID ExAllocatePoolWithTag( |
VOID ExFreePoolWithTag( |
PoolType 是一个位字段,其关联的枚举如下:
NonPagedPool = 0 |
PoolType 中可以存储多项信息:
- 所使用的内存类型,包括
NonPagedPool、PagedPool、SessionPool或NonPagedPoolNx; - 分配操作是否为关键操作(第 1 位)且必须成功。如果分配
失败,将触发BugCheck(系统崩溃); - 分配的内存是否按缓存行大小对齐(第 2 位);
- 分配操作是否使用了 PoolQuota 机制(第 3 位);
- 其他未文档化的机制。
所使用的内存类型至关重要,因为它能将不同的内存分配操作隔离在不同的内存区域中。两种主要的内存类型是PagedPool和 NonPagedPool。MSDN 文档对此作了如下描述:
非分页池(
NonPagedPool)是不可分页的系统内存。它可以在任何 IRQL 级别下被访问,但由于它是一种稀缺资源,驱动程序应仅在必要时才对其进行分配。分页池是可分页的系统内存,仅可在IRQL < DISPATCH_LEVEL的级别下进行分配和访问。
正如第1.2节所述,NonPagedPoolNx 已在 Windows 8 中引入,且必须用于替代 NonPagedPool。
SessionPool 用于会话空间的内存分配,且对于每个用户会话而言都是唯一的。它主要由win32k 组件使用。
最后,标签(Tag)是一个非零的字符字面量,长度为一至四个字符(例如:'Tag1')。建议内核开发人员针对不同的代码路径使用唯一的内存池标签(Pool Tag),以协助调试器和验证工具识别特定的代码路径。
POOL_HEADER:在内存池中,所有能够容纳于单个页面的内存块(Chunk)均以一个 POOL_HEADER 结构体作为起始。该结构体包含了内存分配器所需的各类信息,以及前述的标签。当尝试利用 Windows 内核中的堆溢出(Heap Overflow)漏洞时,首当其冲会被覆盖的便是 POOL_HEADER 结构体。攻击者此时面临两种选择:一是妥善重写 POOL_HEADER 结构体,进而攻击紧邻的下一个内存块中的数据;二是直接针对 POOL_HEADER 结构体本身发起攻击。
在这两种攻击场景中,POOL_HEADER 结构体均会被覆盖;因此,若要成功利用此类漏洞,必须对该结构体中的每一个字段及其具体用途有着透彻的理解。本文将重点探讨那些直接针对 POOL_HEADER 结构体发起的攻击手段。
struct POOL_HEADER |
如图 3 所示的 POOL_HEADER 结构,虽然随时间推移发生过细微演变,但其主要字段始终保持不变。在 Windows 1809 版本中(即 Windows 19H1 之前),该结构的所有字段均处于使用状态:
PreviousSize: 表示前一个内存块的大小除以 16 的值;PoolIndex是PoolDescriptor数组中的一个索引;BlockSize表示当前分配块的大小除以 16 的值;PoolType是一个位字段,用于存储有关分配类型的信息;ProcessBilled是指向执行该内存分配操作的KPROCESS对象的指针。仅当PoolType字段中设置了PoolQuota标志时,该指针才会被赋值。
1.2 自 Windows 7 以来的攻击与缓解措施
Tarjei Mandt 及其论文《Windows 7 内核池利用》(Kernel Pool Exploitation on Windows 7)[5] 是针对内核池攻击领域的权威参考资料。该论文详尽阐述了内核池的内部机制及多种攻击手段,其中部分攻击专门针对 POOL_HEADER 结构。
该论文中所描述的一种攻击手段是“配额进程指针覆盖”(Quota Process Pointer Overwrite)。这种攻击利用堆溢出漏洞,覆盖了已分配内存块(chunk)中的 ProcessBilled 指针。当该内存块被释放时,如果其 PoolType 字段包含 PoolQuota 标志(0x8),系统便会利用该指针进行解引用操作。通过控制这一指针,攻击者便获得了“任意解引用”这一原语,这足以实现从用户态到更高权限的提权。图4展示了这一攻击过程。
自 Windows 8 起,随着 ExpPoolQuotaCookie 的引入,这一攻击手段已得到缓解。该 Cookie 在系统启动时随机生成,用于保护指针免受攻击者的覆盖。例如,它被用于对 ProcessBilled 字段执行异或(XOR)运算:
ProcessBilled = KPROCESS_PTR ^ ExpPoolQuotaCookie ^ CHUNK_ADDR |
当该内存块被释放时,内核会检查编码后的指针是否为一个有效的 KPROCESS 指针:
//ExFreeHeapPool |
若无法获知内存块(chunk)的地址以及 ExpPoolQuotaCookie 的数值,便无法构造出有效的指针,从而也就无法实现任意地址解引用。不过,通过在 PoolType 字段中不设置 PoolQuota 标志位,仍然可以成功重写 POOL_HEADER 结构体,进而实施全面的数据攻击。关于“配额进程指针覆盖攻击”(Quota Process Pointer Overwrite attack)的更多详情,可参阅 Nuit du Hack XV 大会上的相关议题 [1]。
NonPagedPoolNx:自 Windows 8 起,引入了一种新型的内存池类型:NonPagedPoolNx。它的工作机制与 NonPagedPool 如出一辙,唯一的区别在于其内存页不再具备可执行属性;这一特性有效遏制了所有利用此类内存来存储 Shellcode 的攻击手段。此前分配于 NonPagedPool 中的内存资源,现已转由 NonPagedPoolNx 进行分配;不过,NonPagedPool 这一类型仍被保留了下来,主要是为了确保与第三方驱动程序的兼容性。即便在当下的 Windows 10 系统中,仍有大量的第三方驱动程序在使用具备可执行属性的 NonPagedPool。
随着时间的推移,各项缓解措施相继引入,使得利用堆溢出攻击 POOL_HEADER 的手法不再具有吸引力。如今,更简便的攻击方式是妥善重写 POOL_HEADER,进而攻击紧邻的下一个堆块(chunk)中的数据。然而,随着“分段堆”(Segment Heap)机制被引入到内存池中,POOL_HEADER 的使用方式也随之发生了改变;本文将展示如何再次针对 POOL_HEADER 发起攻击,从而利用内核内存池中的堆溢出漏洞。
2 结合分段堆的池分配器
2.1 分段堆的内部机制
自 Windows 10 19H1 版本起,分段堆(Segment Heap)便已应用于内核空间,且其设计与用户空间所使用的分段堆颇为相似。本节旨在介绍分段堆的主要特性,并重点阐述其与用户空间分段堆之间的差异。关于用户空间分段堆内部机制的详尽解析,可参阅文献 [7]。
正如用户空间的分段堆一样,内核分段堆旨在根据分配请求的大小,提供不同的功能特性。为此,系统定义了四种所谓的“后端”(backends)。
- 低碎片堆(Low Fragmentation Heap 简称 LFH):
RtlHpLfhContextAllocate - 可变大小(Variable Size 简称 VS):
RtlHpVsContextAllocateInternal - 段分配(Segment Alloc 简称 Seg):
RtlHpSegAlloc - 大块分配(Large Alloc):
RtlHpLargeAlloc
请求分配大小与所选后端之间的映射如图 5 所示。
前三个后端Seg、VS 和 LFH,分别关联着一个上下文:_HEAP_SEG_CONTEXT、_HEAP_VS_CONTEXT 和 _HEAP_LFH_CONTEXT。这些后端上下文存储在 _SEGMENT_HEAP 结构中。
0: kd> dt nt!_SEGMENT_HEAP |
目前存在 5 种此类结构,分别对应不同的 _POOL_TYPE 值:
NonPaged池(第 0 位未置位)NonPagedNx池(第 0 位未置位,且第 9 位已置位)Paged池(第 0 位已置位)PagedSession池(第 5 位和第 1 位均已置位)
此外还分配了第五个 _SEGMENT_HEAP 结构,但作者未能查明其具体用途。前三个 _SEGMENT_HEAP 结构(分别对应 NonPaged、NonPagedNx 和 Paged 池)均存储在 HEAP_POOL_NODES 中。至于 PagedPoolSession,其对应的 _SEGMENT_HEAP 存储在当前线程中。图 6 总结了这五个 _SEGMENT_HEAP。
尽管用户态分段堆(Segment Heap)对于 128KiB 至 508KiB 范围内的分配仅使用一个分段分配上下文,但在内核态中,分段堆使用了两个分段分配上下文。其中第二个上下文用于 508KiB 至 7GiB 范围内的分配。
Segment Backend
段后端(Segment Backend)用于分配大小介于 128KiB 和 7GiB 之间的内存块。此外,它还在幕后挥作用,为 VS 和 LFH 后端分配内存。段后端的上下文信息存储在一个名为 _HEAP_SEG_CONTEXT 的结构体中。
0: kd> dt nt!_HEAP_SEG_CONTEXT |
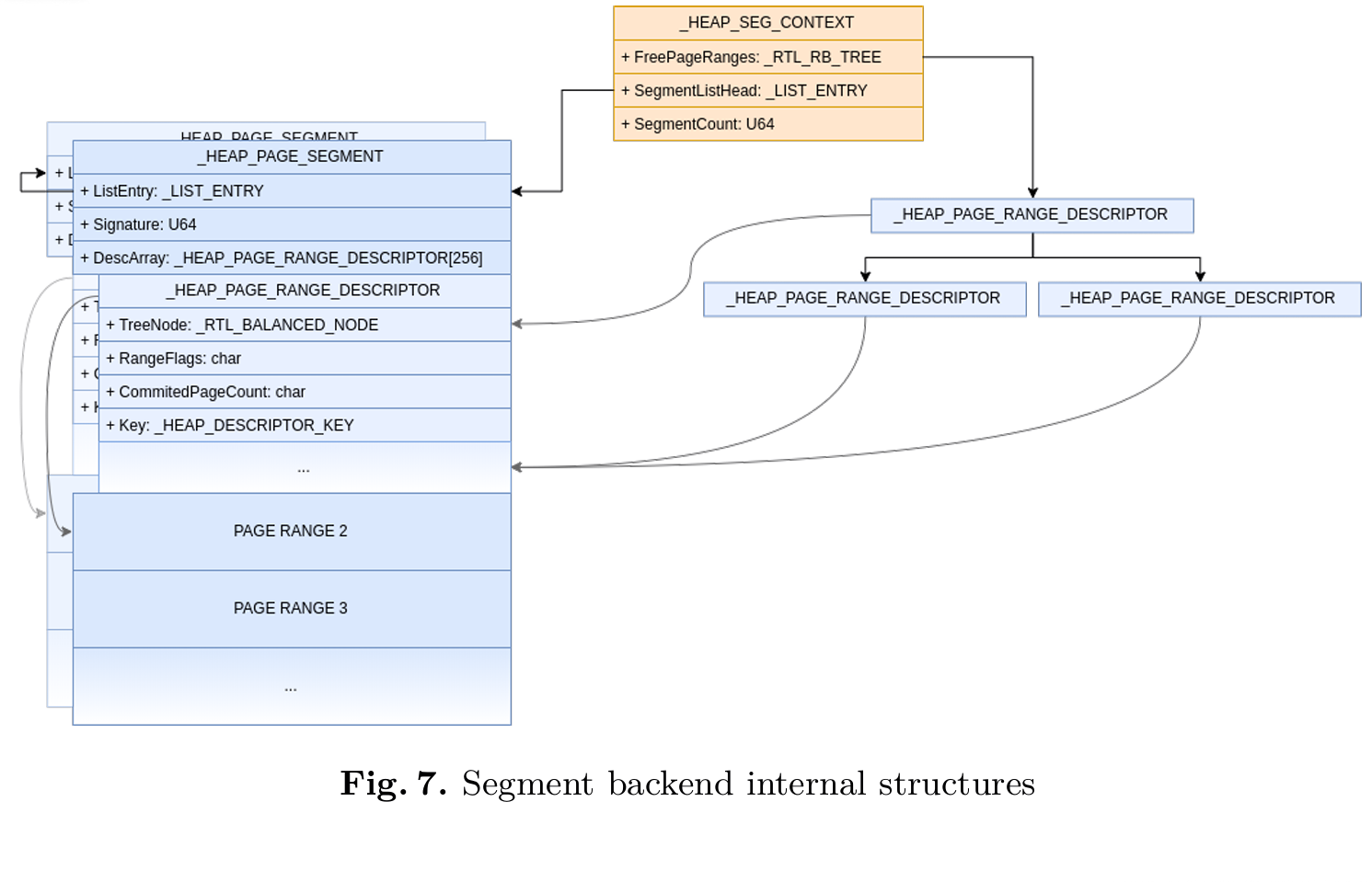
段后端(Segment Backend)以大小可变的块为单位分配内存,这些块被称为“段”(segments)。每个段均由多个可分配的页组成。
这些段存储在一个链表中,该链表的头指针保存在 SegmentListHead 中。每个段的起始处包含一个 _HEAP_PAGE_SEGMENT 结构,紧随其后的是 256 个_HEAP_PAGE_RANGE_DESCRIPTOR 结构。
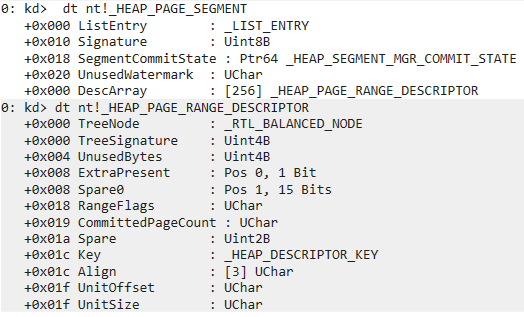
0: kd> dt nt!_HEAP_PAGE_SEGMENT |
0: kd> dt nt!_HEAP_PAGE_RANGE_DESCRIPTOR |
为了实现对空闲页范围的快速查找,_HEAP_SEG_CONTEXT 中也维护了一棵红黑树。每个 _HEAP_PAGE_SEGMENT 均包含一个签名,其计算方式如下(RtlpHpSegHeapAddSegment):
Signature = Segment ^ SegContext ^ RtlpHpHeapGlobals ^ 0xA2E64EADA2E64EAD |
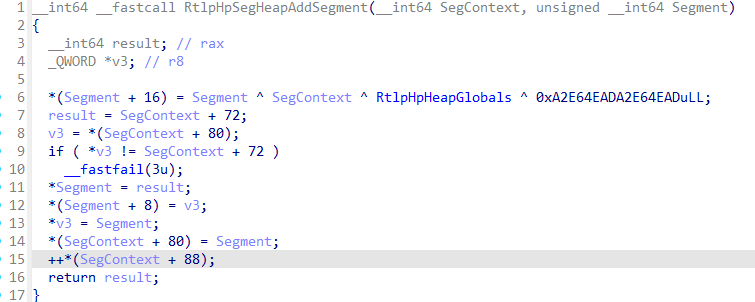
该签名用于从任意已分配的内存块中,检索其所属的 _HEAP_SEG_CONTEXT 结构以及相应的 _SEGMENT_HEAP 结构。
图 7 概述了段后端(segment backend)所使用的内部结构。
对于任意给定的地址,只需利用存储在 _HEAP_SEG_CONTEXT 中的 SegmentMask 进行掩码操作,即可轻松计算出其对应的原始段。SegmentMask 的取值为 0xfffffffffff00000。
Segment = Addr & SegContext->SegmentMask; |
利用 _HEAP_SEG_CONTEXT 中的 UnitShift,即可根据任意地址轻松计算出相应的 PageRange。其中,UnitShift 的值被设定为 12。
PageRange = Segment + sizeof(_HEAP_PAGE_RANGE_DESCRIPTOR) * (Addr- Segment) >> SegContext->UnitShift; |
当 Segment 后端被其他后端之一使用时,_HEAP_PAGE_RANGE_DESCRIPTOR 结构体中的 RangeFlags 字段被用于存储是哪个后端请求了此次分配。
Variable Size Backend
变长分配后端(Variable Size backend)负责分配大小介于 512(0x200) 字节至 128 KiB 之间的内存块。其旨在便于对空闲内存块进行复用。
变长分配后端的上下文信息存储在一个名为 _HEAP_VS_CONTEXT 的结构体中。
0: kd> dt nt!_HEAP_VS_CONTEXT |

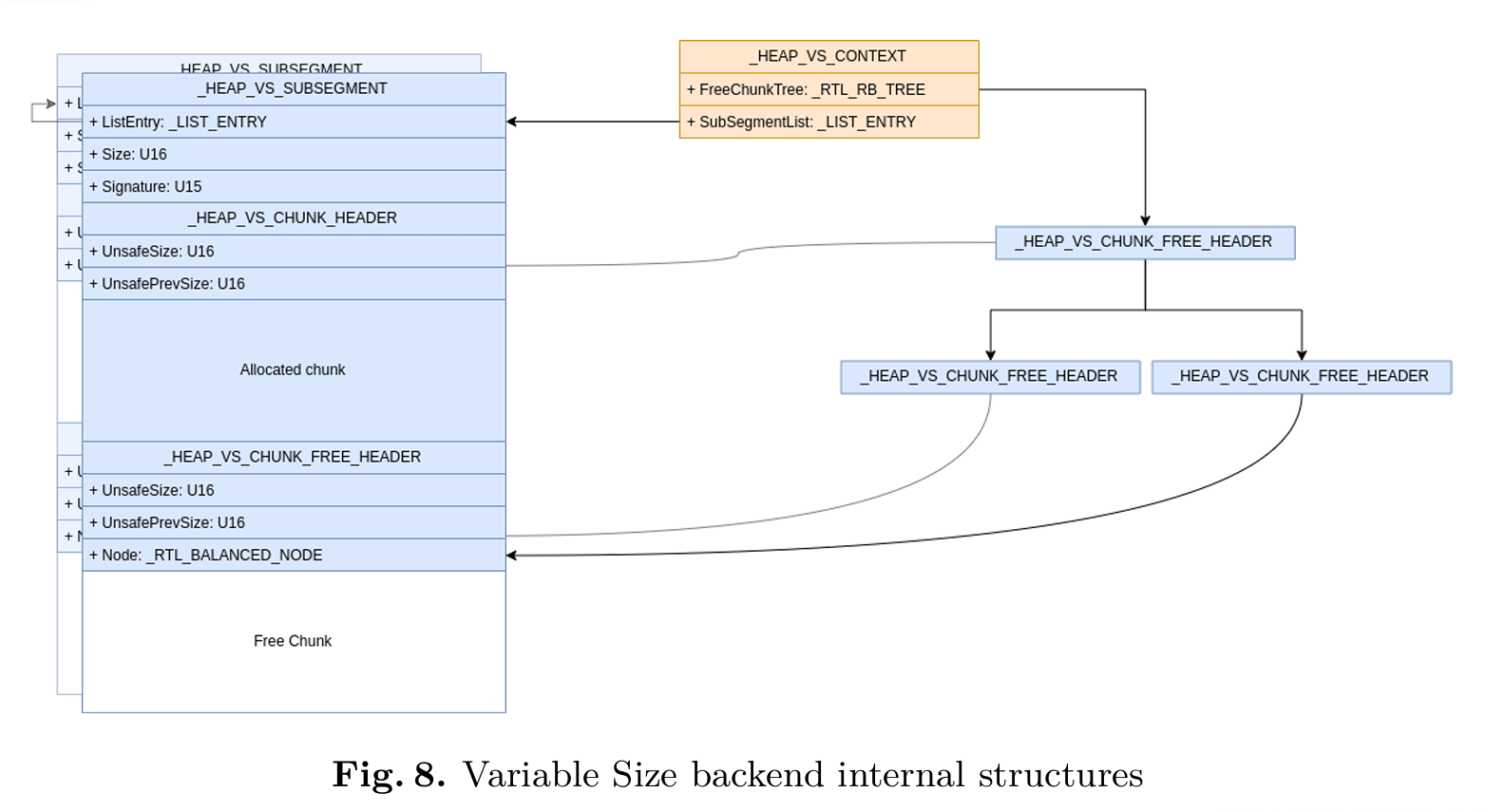
空闲块存储在一棵名为 FreeChunkTree 的红黑树中。当收到分配请求时,系统会利用这棵红黑树来查找大小完全匹配的空闲块,或者查找首个大小大于请求大小的空闲块。
被释放的空闲块头部带有一个专用的结构体,名为_HEAP_VS_CHUNK_FREE_HEADER。
0: kd> dt nt!_HEAP_VS_CHUNK_FREE_HEADER |

一旦找到空闲块,便通过调用 RtlpHpVsChunkSplit 将其拆分为合适的大小。
所有已分配的块均以一个名为 _HEAP_VS_CHUNK_HEADER 的专用结构体作为头部。
0: kd> dt nt!_HEAP_VS_CHUNK_HEADER |
此标头内的所有字段均与 RtlpHpHeapGlobals 以及块的地址进行异或运算。
Chunk->Sizes = Chunk->Sizes ^ Chunk ^ RtlpHpHeapGlobals; |

在内部,VS 分配器利用了 RtlpHpVsSubsegmentCreate 分配器。具体而言,它是通过访问_HEAP_VS_CONTEXT 结构体中的 _HEAP_SUBALLOCATOR_CALLBACKS 字段来实现这一点的。这些子分配器回调函数的地址均与 VS 上下文(VS context)及 RtlpHpHeapGlobals 的地址进行了异或(XOR)运算。
callbacks.Allocate = RtlpHpSegVsAllocate; |
如果在 FreeChunkTree 中不存在足够大的内存块(Chunk),系统将分配一个新的 Subsegment(其大小范围为 64KiB 至 256KiB),并将其插入到 SubsegmentList 中。该 Subsegment 的头部包含一个 _HEAP_VS_SUBSEGMENT 结构。剩余的所有空间将被用作一个空闲块,并被插入到 FreeChunkTree 中。
0: kd> dt nt!_HEAP_VS_SUBSEGMENT |
当一个 VS 块被释放时,如果其大小小于 1KiB,且 VS 后端已正确配置(即 Config.Flags 的第 4 位被设置为 1),该块将被暂时存储在 DelayFreeContext 内部的一个列表中。一旦 DelayFreeContext中存满了 32 个块,这些块便会被一次性全部真正释放。DelayFreeContext 绝不用于直接分配内存。
当一个 VS 块被真正释放时,如果它与另外两个已释放的块相邻,这三个块将通过调用RtlpHpVsChunkCoalesce 合并在一起。随后,该块将被插入到 FreeChunkTree 中。
Low Fragmentation Heap Backend
低碎片堆(LFH)是一个专门用于处理 1 字节至 512 字节小规模内存分配的后端。
LFH 后端上下文存储在一个名为 _HEAP_LFH_CONTEXT 的结构体中。
0: kd> dt nt!_HEAP_LFH_CONTEXT |
LFH 后端的主要特性是利用不同大小的桶来避免碎片化。
| Bucket | Allocation Size | Bucket granularity |
|---|---|---|
| 1– 64 | 1B– 1008B | 16B |
| 65– 80 | 1009B– 2032B | 64B |
| 81– 96 | 2033B– 4080B | 128B |
| 97– 112 | 4081B– 8176B | 256B |
| 113– 128 | 8177B– 16368B | 512B |
每个桶(Bucket)均由段分配器(Segment Allocator)所分配的子段(SubSegments)组成。段分配器的使用是通过 _HEAP_LFH_CONTEXT 结构体中的 _HEAP_SUBALLOCATOR_CALLBACKS 字段来实现的。这些子分配器回调函数的地址均与 LFH 上下文及 RtlpHpHeapGlobals 的地址进行了异或(XOR)运算。
callbacks.Allocate = RtlpHpSegLfhAllocate; |
LFH 子段以 _HEAP_LFH_SUBSEGMENT 结构作为开头。
0: kd> dt nt!_HEAP_LFH_SUBSEGMENT |
随后,每个子段会被拆分为不同的 LFH 块,并对应以特定的桶大小。为了标识哪些桶已被使用,每个子段的头部均维护有一个位图。
当收到分配请求时,LFH 分配器首先会查找 _HEAP_LFH_SUBSEGMENT 结构中的 FreeHint 字段,以此确定该子段(SubSegment)内上一个已释放块的偏移量。随后,它将以每 32 个块为一组,扫描 BlockBitmap 以寻找空闲块。得益于 RtlpLowFragHeapRandomData 表,这一扫描过程具有随机性
根据特定桶(Bucket)所面临的竞争程度,系统可能会启用一种机制来缓解分配压力,具体做法是为每个 CPU 分配专用的子段。这一机制被称为“亲和槽”(Affinity Slot)。
图 9 展示了 LFH 后端的主要架构。
Dynamic Lookaside
大小介于 0x200 到 0xF80 字节之间的已释放内存块,可暂时存储在“前瞻列表”(lookaside list)中,以实现快速分配。当这些内存块处于前瞻列表中时,它们将不会经过各自对应的后端释放机制进行处理。
前瞻列表由 _RTL_DYNAMIC_LOOKASIDE 结构体表示,并存储在 _SEGMENT_HEAP 结构体的 UserContext 字段中。
0: kd> dt nt!_RTL_DYNAMIC_LOOKASIDE |
每个已释放的块均存储在其大小所对应的 _RTL_LOOKASIDE结构中(该大小由 POOL_HEADER 标头指定)。这种大小对应关系遵循与 LFH 中的 Bucket 相同的模式。
0: kd> dt nt!_RTL_LOOKASIDE |
| Free List | Allocation Size | Bucket granularity |
|---|---|---|
| 1– 32 | 512B– 1024B | 16B |
| 33– 48 | 1025B– 2048B | 64B |
| 49– 64 | 2049B– 3967B | 128B |
在同一时刻,仅有一部分可用桶处于启用状态(即 _RTL_DYNAMIC_LOOKASIDE 结构体中的 ActiveBucketCount 字段)。每当发起一次分配请求时,相应 Lookaside 列表的各项指标便会随之更新。
每进行 3 次 Balance Set Manager 扫描,动态预查缓冲区(dynamic lookaside)便会进行一次重新平衡。自上次重新平衡以来使用频率最高的部分将被启用。每个预查缓冲区的大小取决于其使用情况,但不得超过 MaximumDepth 设定的上限,亦不得少于 4。若新增分配的数量少于 25,则深度减小 10。反之,若未命中率低于 0.5%,深度则减小 1;否则,深度将依据以下公式进行增加。
2.2 POOL_HEADER
正如第 1.1 节所述,在 Windows 10 19H1 版本之前的内核堆分配器中,POOL_HEADER 结构体位于所有已分配内存块的头部。当时,该结构体中的所有字段均被使用。随着内核堆分配器的更新,POOL_HEADER 中的大多数字段已变得无用,但对于那些较小的已分配内存块而言,其头部仍旧包含该结构体。POOL_HEADER 的定义如图 10 所示。
struct POOL_HEADER |
分配器设置的字段仅包括以下各项:
PoolHeader->PoolTag = PoolTag; |
以下是自 Windows 19H1 版本以来,各个 POOL_HEADER 字段用途的摘要。
- PreviousSize: Unused and kept to 0.
- PoolIndex:未使用。
- BlockSize:块(chunk)的大小。仅用于最终将该块存储到动态查找列表(Dynamic Lookaside list)中(参见 2.1 节)。
- PoolType:用途未变;用于保存所请求的
POOL_TYPE类型。 - PoolTag:用途未变;用于保存 PoolTag 标签。ProcessBilled:用途未变;当 PoolType 为 PoolQuota(第 3 位)时,用于追踪是哪个进程发起了此次内存分配请求。其取值计算方式如下:
ProcessBilled = chunk_addr ^ ExpPoolQuotaCookie ^ KPROCESS
CacheAligned
在调用 ExAllocatePoolWithTag 时,如果 PoolType 参数设置了 CacheAligned 位(即第 2 位),则返回的内存将按缓存行大小进行对齐。缓存行大小的具体数值取决于 CPU 架构,但通常为 0x40。
首先,分配器会将分配大小增加 ExpCacheLineSize 的数值:
if ( PoolType & 4 ) |
如果新的分配大小无法容纳于单个页面内,则 CacheAligned 位将被忽略。
此时,所分配的内存块必须满足以下三个条件:
- 最终分配地址必须按
ExpCacheLineSize对齐; - 该块(chunk)的起始位置必须包含一个
POOL_HEADER; - 该块在分配地址减去 sizeof(
POOL_HEADER) 处,必须包含一个POOL_HEADER。
因此,如果分配地址未正确对齐,该内存块(chunk)可能包含两个头部。
第一个 POOL_HEADER 照例位于内存块的起始位置;而第二个 POOL_HEADER 则会按照ExpCacheLineSize 的大小进行对齐(即位于距离起始位置 ExpCacheLineSize 处),从而确保最终的分配地址能够对齐到 ExpCacheLineSize。第一个 POOL_HEADER 中的 CacheAligned 位会被移除,而第二个 POOL_HEADER 则填充有以下数值:
- PreviousSize:用于存储两个头部结构体之间的偏移量。
- PoolIndex:未使用。
- BlockSize:在第一个 POOL_HEADER 中存储的是所分配内存桶的完整大小;而在第二
POOL_HEADER中,该数值则为缩减后的(较小)大小。 - PoolType:照常设置,但其中的 CacheAligned 位会被置位。
- PoolTag:照常设置,两个 POOL_HEADER 中的该数值保持一致。
- ProcessBilled:未使用。
此外,如果在对齐填充区域(alignment padding)中尚有足够的空间,则可能会在第一个 POOL_HEADER 之后存储一个指针(我们将其命名为 AlignedPoolHeader)。该指针指向第二个 POOL_HEADER,且其数值经过了与 ExpPoolQuotaCookie 的异或(XOR)运算处理。
图 11 总结并展示了在启用缓存对齐(cache alignment)机制时,这两个 POOL_HEADER 的具体内存布局。
2.3 Summary
自 Windows 19H1 版本引入 Segment Heap 机制以来,原本存储在每个内存块(Chunk)的 POOL_HEADER 中的部分信息已不再是必需的。然而,诸如 PoolType、PoolTag,以及对 CacheAligned 和 PoolQuota 机制的支持等其他信息,依然是不可或缺的。
正因如此,所有小于 0xFE0 的分配块前方仍至少包含一个 POOL_HEADER。自 Windows 19H1 版本起,POOL_HEADER 各字段的用法已在第 2.2 节中进行了描述。图 12 展示了一个通过 LFH 后端分配的内存块,因此其前方仅包含一个 POOL_HEADER。

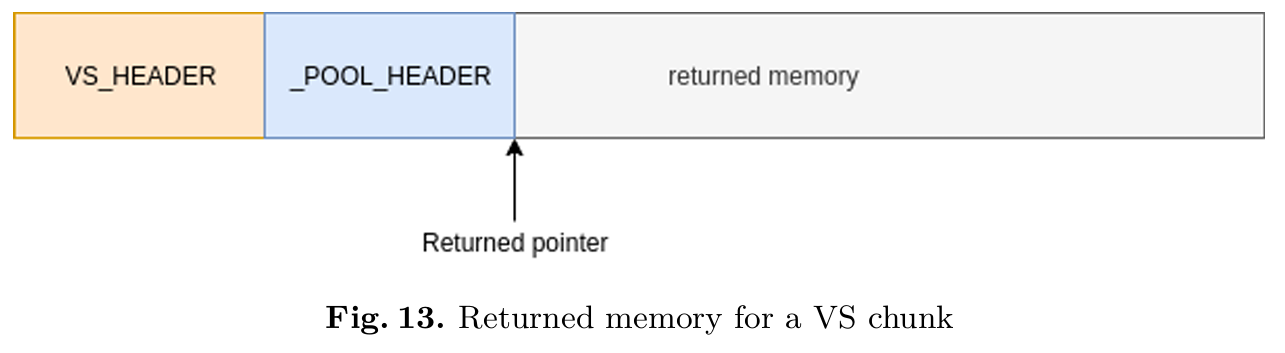
正如第 2.1 节所述,视后端类型而定,内存块的起始处可能会附带特定的头部结构。例如,一个大小为 0x280 的内存块将采用 VS 后端,因此其前方会紧接着一个大小为 0x10 的_HEAP_VS_CHUNK_HEADER 结构。图 13 展示了一个通过 VS 段分配的内存块,因此其前方依次包含一个 VS 头部和一个 POOL_HEADER 结构。
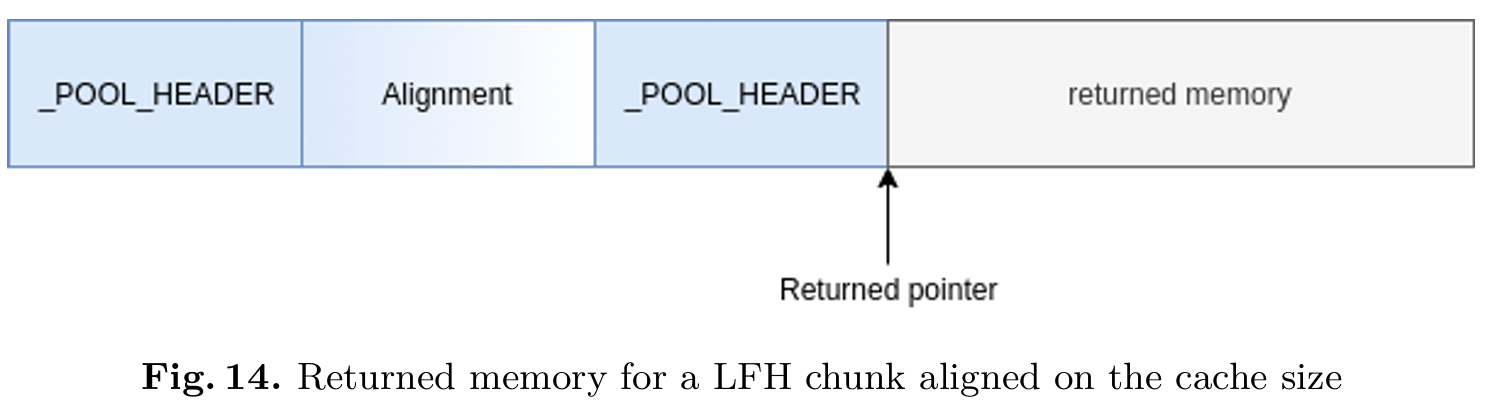
最后,如果请求的内存分配需要按缓存行(cache line)对齐,则该内存块(chunk)中可能会包含两个 POOL_HEADER 结构。其中的第二个结构会设置 CacheAligned 位,并用于回溯定位第一个结构,以及获取实际分配内存的起始地址。图 14 展示了一个通过 LFH(低碎片堆)分配、且被要求按缓存大小对齐的内存块;正因如此,该内存块的前端紧接着两个 POOL_HEADER 结构。
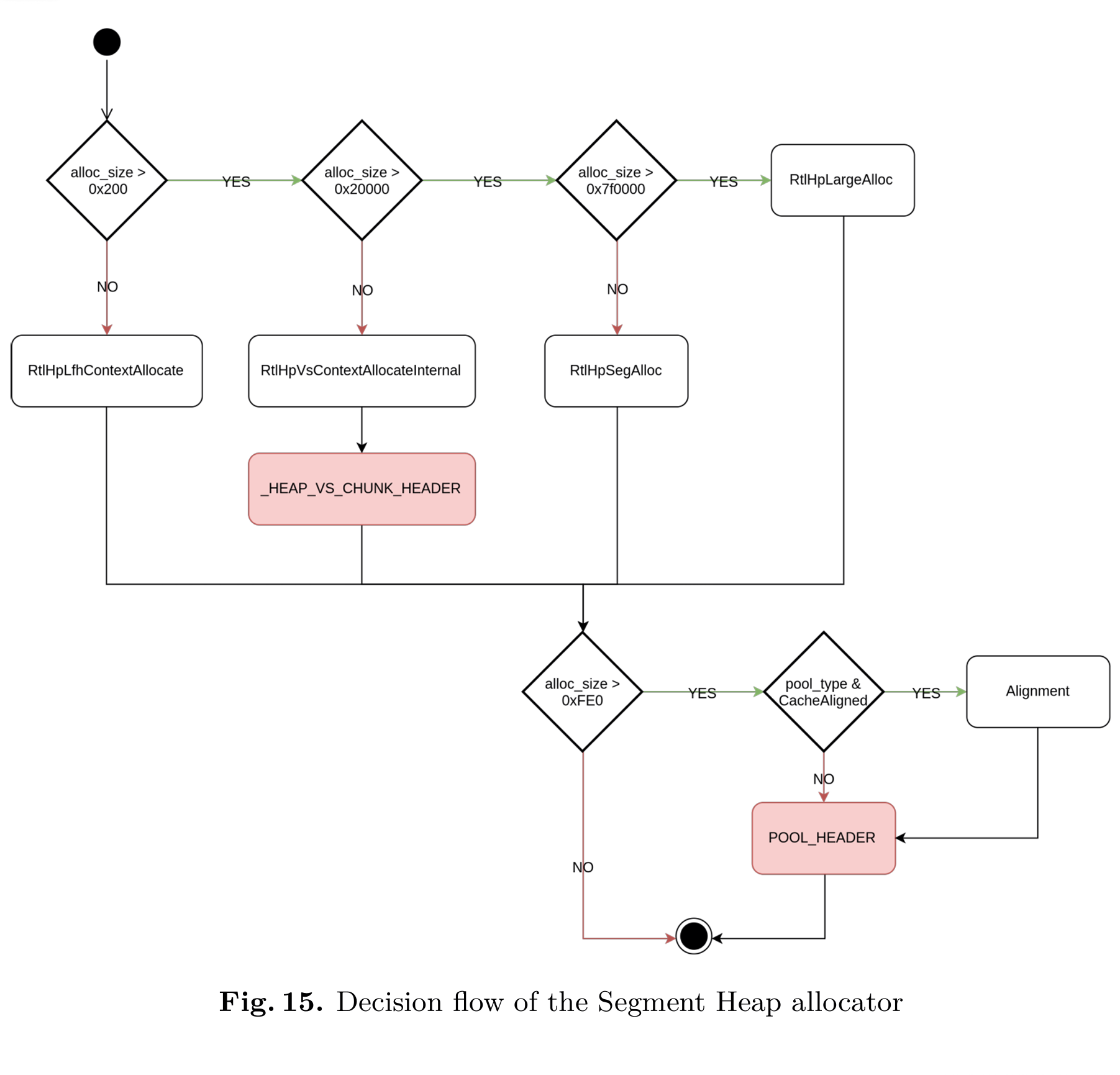
图 15 总结了在执行内存分配操作时所采用的决策树流程。
从漏洞利用(exploitation)的角度来看,可以得出两个结论。首先,POOL_HEADER 的这种新式用法将降低漏洞利用的难度:由于该结构中的大多数字段均未被使用,因此在对其进行覆盖(overwriting)操作时,无需像以往那样顾虑重重。另一个潜在的成果是,可以利用 POOL_HEADER 的这一新特性,
探索并发掘出全新的漏洞利用技术。
3. 攻击 POOL_HEADER
如果堆溢出漏洞允许攻击者对写入数据及其大小实现高度精确的控制,那么最简单的解决方案莫过于重写 POOL_HEADER,并直接针对紧邻的下一个堆块(chunk)的数据发起攻击。此时唯一需要确保的是:PoolType 字段中的 PoolQuota 位未被设置,从而避免在受损堆块被释放时触发针对 ProcessBilled 字段的完整性检查。
然而,本节将介绍一些仅凭数个字节的堆溢出便可实施的攻击手段,这些攻击主要通过针对 POOL_HEADER 结构体来实现。
3.1 Targeting the BlockSize
From Heap Overflow to bigger Heap Overflow
正如第 2.1 节所述,BlockSize 字段在内存释放机制中用于将某些内存块(chunk)存入“动态旁路列表”(Dynamic Lookaside)中。
攻击者可以利用堆溢出漏洞,将 BlockSize 字段的值篡改为一个更大的数值,使其超过 0x200。一旦这个被篡改的内存块被释放,系统便会依据这个受控的 BlockSize 值,将其存入一个尺寸错误的旁路列表中。随后若发生针对该特定尺寸的内存分配请求,系统可能会分配一个过小的内存块来存储所需数据,从而引发另一次堆溢出。
通过结合“堆喷射”(spraying)技术及特定的对象操作,攻击者能够将原本仅 3 字节的堆溢出,放大为高达 0xFD0 字节的大规模堆溢出——具体溢出规模取决于受害内存块的原始大小。此外,这种攻击手段还赋予了攻击者选择具体哪个对象发生溢出的能力,并使其能够对溢出发生时的各项条件拥有更强的掌控力。
3.2 Targeting the PoolType
在大多数情况下,存储在 PoolType 字段中的信息仅具参考价值;这些信息是在内存分配时指定的并被存入 PoolType 中,但在内存释放机制中并不会被实际使用。
例如,即使更改 PoolType 中所记录的内存类型,也不会真正改变该次分配实际使用的内存类型。仅仅通过修改这一位,是不可能将 NonPagedPoolNx 类型的内存转换为 NonPagedPool 类型的。
然而,对于 PoolQuota 和 CacheAligned 这两个位而言,情况并非如此。若设置了 PoolQuota 位,系统便会在内存释放时,利用 POOL_HEADER 结构体中的 ProcessBilled 指针来执行配额扣减操作。正如第 1.2 节所述,针对 ProcessBilled 指针的攻击手段目前已得到缓解。
因此,唯一剩下的部分就是 CacheAligned 位。
Aligned Chunk Confusion
正如第 2.2 节所述,如果请求分配时 PoolType 字段设置了 CacheAligned 位,则该内存块(chunk)的布局会有所不同。
当分配器释放此类分配时,它会尝试查找原始内存块的地址,以便在正确的地址处执行释放操作。为此,它将利用对齐后的 POOL_HEADER 中的 PreviousSize 字段。分配器只需执行一次简单的减法运算,即可计算出原始内存块的地址:
if ( AlignedHeader->PoolType & 4 ) |
在内核引入分段堆(Segment Heap)之前,上述操作之后通常会伴随几项检查:
- 分配器会检查原始内存块(chunk)的
PoolType字段中是否设置了MustSucceed位。 - 分配器会利用
ExpCacheLineSize重新计算两个头部之间的偏移量,并验证该计算值是否与两个头部之间的实际偏移量相吻合。 - 分配器会检查对齐后的头部(aligned header)的
BlockSize是否等于原始头部的BlockSize加上对齐后头部的PreviousSize。 - 分配器会检查位于
OriginalHeader + sizeof(POOL_HEADER)处的指针值,看其是否等于对齐后头部的地址与ExpPoolQuotaCookie进行异或运算后的结果。
自 Windows 10 19H1 版本起,由于内存池分配器(pool allocator)开始采用分段堆机制,上述所有检查均已被移除。虽然那个经过异或运算处理的指针仍旧紧随在原始头部之后,但释放机制在执行过程中已不再对其进行任何检查。作者推测,其中部分检查可能是因疏忽而被错误移除的。尽管未来发布的版本中很有可能会重新启用部分检查,但目前已知的 Windows 10 20H1 预发布版本中尚未包含此类修补程序。
就目前而言,由于缺乏相应的检查机制,攻击者得以利用 PoolType 字段作为攻击媒介。攻击者可以利用堆溢出漏洞,将紧邻的下一个内存块的 PoolType 字段中的 CacheAligned 位设置为开启状态,并借此完全掌控该内存块的 PreviousSize 字段。当该内存块被执行释放操作时,释放机制便会依据攻击者所控制的 PreviousSize 值来定位并释放其前方的原始内存块。 由于 PreviousSize 字段仅占用一个字节的存储空间,攻击者能够释放位于原始内存块(chunk)地址之前、且地址对齐至 0x10 的任意地址(范围上限为 0xFF * 0x10 = 0xFF0)。
本文的最后一部分旨在演示一种通用的漏洞利用方法,该方法综合运用了前文所介绍的各项技术。本节将列举在发生内存池溢出(Pool Overflow)或“释放后重用”(Use-After-Free)漏洞场景时,那些值得攻击者加以控制的通用对象;此外,还将介绍多种对象及技术手段,用以实现对已释放内存块的重用,并向其中写入受控数据。
4. 通用利用
4.1 必要条件
本节旨在介绍利用特定漏洞在 Windows 系统上实现权限提升的技术。在此假设攻击者当前处于“低完整性”(Low Integrity)级别。
最终目标是开发一种尽可能通用的漏洞利用程序,使其能够适用于不同类型的内存池(包括 PagedPool 和 NonPagedPoolNx)、不同大小的内存块(Chunk),以及任何满足以下必要条件的堆溢出漏洞:
- 当针对“块大小”(BlockSize)进行攻击时,该漏洞必须允许攻击者将下一个内存块(Chunk)的
POOL_HEADER结构中的第 3 个字节改写为由攻击者控制的数值。 - 当针对“内存池类型”(
PoolType)进行攻击时,该漏洞必须允许攻击者将下一个内存块(Chunk)的POOL_HEADER结构中的第 1 个和第 4 个字节改写为由攻击者控制的数值。 - 在所有情况下,攻击者都必须能够控制目标漏洞对象(Vulnerable Object)的分配与释放过程,从而最大程度地提高“堆喷射”(Heap Spraying)攻击的成功率。
4.2 利用策略
所选用的利用策略利用了攻击下一个内存块(chunk)的 POOL_HEADER 结构中 PoolType 和PreviousSize 字段的能力。受堆溢出漏洞影响的内存块被称为“易受攻击块”(vulnerable chunk),紧随其后的内存块则被称为“被覆盖块”(overwritten chunk)。
正如第 3.2 节所述,通过控制下一个内存块 POOL_HEADER 中的 PoolType 和 PreviousSize 字段,攻击者可以改变“被覆盖块”实际被释放时的目标地址。这一原语(primitive)可以通过多种方式加以利用。
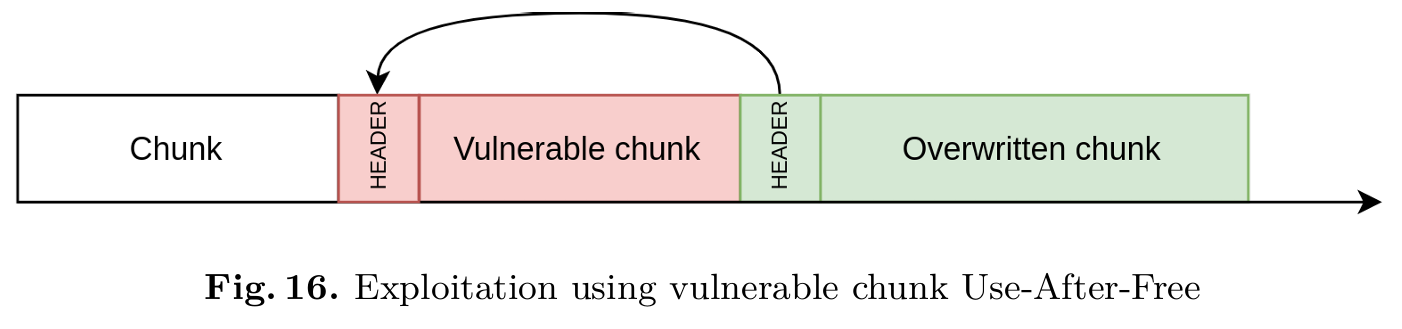
这使得攻击者能够利用池溢出漏洞制造“释放后重用”(Use-After-Free)场景;具体而言,攻击者会将 PreviousSize 字段设置为恰好等于受漏洞影响的内存块(chunk)的大小。因此,当系统尝试释放被覆盖的内存块时,实际被释放的却是那个受漏洞影响的内存块,从而引发“释放后重用”问题。图 16 展示了这一攻击技术。
然而,最终选用了另一种技术。利用该原语,还可以触发位于易受攻击块(vulnerable chunk)中间的被覆盖块(overwritten chunk)的释放操作。具体而言,可以在易受攻击块内部(或用于替换它的块内部)伪造一个虚假的 POOL_HEADER,随后利用“PoolType 攻击”来重定向针对该块的释放流程。通过这种方式,便能在一个合法的块内部凭空构造出一个虚假的块,从而营造出一种极具优势的溢出攻击局面。我们将这个对应的块称为“幽灵块”(ghost chunk)。
该幽灵块至少覆盖了两个块:即易受攻击块本身,以及那个被覆盖的块。图 17 展示了这一技术。
相比“释放后重用”(Use-After-Free)技术,这最后一种技术似乎更具可利用性,因为它能让攻击者处于更有利的地位,从而控制任意对象的内容。
随后,这个存在漏洞的内存块(chunk)可以被重新分配给一个允许进行任意数据控制的对象。这使得攻击者能够部分控制分配在“幽灵块”(ghost chunk)中的对象。
为了将对象放置在“幽灵块”中,必须先找到一个合适的、具有利用价值的对象。为了实现尽可能通用的漏洞利用,该对象应满足以下要求:
- 若能对其进行完全或部分控制,则应能提供“任意读/写”原语;
- 能够控制其分配与释放过程;
- 具有可变大小,且最小尺寸不小于 0x210(以便能从对应的 Lookaside 列表中分配到“幽灵块”中),
但同时应尽可能小(以避免在分配时过度破坏堆内存的结构)。
由于存在漏洞的内存块既可能位于 PagedPool(分页池)中,也可能位于 NonPagedPoolNx(不可分页池)中,因此需要找到两个此类对象:一个分配在 PagedPool 中,另一个分配在 NonPagedPoolNx 中。
这类对象并不常见,作者也未能找到这种“完美”的对象。正因如此,作者开发了一种利用策略,转而使用一种仅提供“任意读”原语的对象。攻击者依然能够控制“幽灵块”的 POOL_HEADER(池头)。这意味着可以利用“配额指针进程覆盖”(Quota Pointer Process Overwrite)攻击,从而获取一个“任意递减”原语。利用该“任意读”原语,攻击者即可恢复 ExpPoolQuotaCookie 的值以及“幽灵块”的地址。本文所开发的漏洞利用程序正是采用了这一技术。
通过结合“堆整形”(heap massaging)技术以及针对特定对象的溢出利用,攻击者能够将原本仅 4 字节的可控溢出转化为一次“权限提升”攻击,从而将权限从“低完整性级别”(Low Integrity Level)提升至 SYSTEM 级别。
4.3 目标对象
PagedPool:在管道创建完成后,用户可以向该管道添加属性。这些属性以键值对的形式存在,并存储于链表中。PipeAttribute1 对象在分页池(Paged Pool)中分配,其在内核中的定义如图 18 所示的结构体。
struct PipeAttribute { |
分配的大小及其中的数据完全受攻击者控制。AttributeName 和 AttributeValue 均为指针,分别指向数据字段内的不同偏移位置。
如图 19 所示,利用 NtFsControlFile 系统调用并配合控制码 0x11003C,即可在管道上创建管道属性。
HANDLE read_pipe; |
随后,可以使用控制码 0x110038 来读取该属性的值。其中的 AttributeValue 指针和 AttributeValueSize 字段将被用于读取属性值,并将其返回给用户。该属性的值是可以更改的;不过,这一操作将触发对前一个 PipeAttribute 对象的释放(deallocation),并随后分配一个新的对象。
这意味着,如果攻击者能够控制 PipeAttribute 结构体中的 AttributeValue 和 AttributeValueSize 字段,他们便能够读取内核中的任意数据,但无法进行任意写入操作。此外,该对象也是向内核中植入任意数据的绝佳载体。换言之,攻击者可以利用它来重新分配(realloc)存在漏洞的内存块(chunk),进而控制“幽灵块”(ghost chunk)的内容。
NonPagedPoolNx:利用 WriteFile 函数向管道(pipe)写入数据,是一种已知的用于对 NonPagedPoolNx 内存池进行“喷射”(spray)的技术。当数据被写入管道时,NpAddDataQueueEntry 函数会创建如图 20 所示的结构体。
struct PipeQueueEntry |
PipeQueueEntry2 的数据及大小均由用户控制,因为其数据直接存储在该结构体之后。
当在 NpReadDataQueue 函数中使用该条目时,内核将遍历条目列表,并利用每一个条目来检索数据。
if ( PipeQueueEntry->isDataAllocated == 1 ) |
如果 isDataInKernel 字段的值为 1,则数据并非直接存储在该结构体之后,而是存储在一个由 linkedIRP 指针所指向的 IRP(I/O 请求包)中。如果攻击者能够完全控制该结构体,他可以将 isDataInKernel 设置为 1,并使 linkedIRP 指向用户空间地址。随后,位于用户空间的该 linkedIRP 结构体中的 SystemBuffer 字段(偏移量 0x18)将被用于从该条目中读取数据。这提供了一种“任意读取”原语。此外,该对象也非常适合用于向内核中写入任意数据。这意味着它可以被用来重新分配(realloc)存在漏洞的内存块(chunk),进而控制“幽灵块”(ghost chunk)的内容。
4.4 Spraying
本节描述了用于对内核堆进行“堆喷射”(heap spraying)的技术,旨在获得所需的内存布局。
为了实现第4.2节中展示的必要内存布局,必须执行一定的堆喷射操作。堆喷射的具体策略取决于目标漏洞块(vulnerable chunk)的大小,因为不同大小的块最终会被分配到不同的后端管理器中。
为了简化喷射过程,确保相应的“旁视列表”(lookaside list)处于清空状态通常会很有帮助。分配超过256个具有特定大小的块,即可确保达到这一状态。
如果目标漏洞块的大小小于0x200字节,它将被分配至“低碎片堆”(LFH)后端。此时,进行堆喷射时应使用大小完全一致的块(在考虑对应桶粒度取模后),以确保所有这些块都从同一个桶(bucket)中分配出来。正如第2.1节所述,当收到分配请求时,LFH后端会以最多32个块为一组扫描“块位图”(BlockBitmap),并从中随机选取一个空闲块。因此,在分配目标漏洞块的前后时刻,额外分配超过32个块,将有助于抵消这种随机化机制的影响。
如果目标漏洞块的大小介于0x200和0x10000字节之间,它将被分配至“变长堆”(Variable Size)后端。此时,进行堆喷射时应使用大小与目标漏洞块完全相等的块。若使用更大的块进行喷射,这些块可能会被拆分,从而导致喷射失败。首先,分配数千个选定大小的块;此举旨在确保两点:一是清空“空闲块树”(FreeChunkTree)中所有大于选定大小的块;二是迫使分配器分配一个新的、大小为0x10000字节的VS子段(subsegment),并将其插入到“空闲块树”中。随后,再分配数千个块,这些块最终将被分配自上述那个新创建的大型空闲块中,从而确保它们在内存上是连续排列的。接着,释放最后分配的那批块中的三分之一,以此来填充“空闲块树”。仅释放三分之一的块,可以确保这些被释放的块之间不会发生合并(coalescing)。随后,允许目标漏洞块被分配。最后,可以将之前释放的那些块重新进行分配,从而最大化堆喷射成功的几率。
鉴于完整的漏洞利用技术需要对易受攻击的内存块(vulnerable chunk)和“幽灵块”(ghost chunk)进行先释放后重分配操作,因此启用相应的动态旁路列表(dynamic lookaside)以简化已释放内存块的回收过程,将是一项非常值得尝试的策略。为此,一个简便的解决方案是:首先分配数千个特定大小的内存块,等待 2 秒;随后再分配数千个同等大小的内存块,并等待 1 秒。通过这一操作,我们可以确保“平衡集管理器”(Balance Set Manager)已对相应的旁路列表完成了重新平衡。分配数千个内存块不仅能确保该旁路列表跻身“高频使用列表”之列从而被正式启用,同时也保证了该列表中拥有充足的可用空间。
4.5 Exploitation
演示环境设置:为了演示接下来的漏洞利用过程,我们特意创建了一个伪造的漏洞。
为此,我们开发了一个 Windows 内核驱动程序,该驱动程序暴露了几个 IOCTL(I/O 控制代码)接口,允许执行以下操作:
-
在分页池(PagedPool)中分配一个大小可控的内存块(chunk);
-
在该内存块内触发一次可控的
memcpy操作,从而实现完全可控的池溢出(pool overflow); -
释放已分配的内存块。
当然,这仅仅是为了演示目的;相比实际漏洞利用所需的最低控制权限,该设置提供了更多的控制能力。
通过这一设置,攻击者能够实现以下目标:
- 控制受漏洞影响的内存块(vulnerable chunk)的大小。虽然这不是强制要求,但通常是首选做法,因为在大小可控的情况下,漏洞利用过程会变得更加容易。
- 控制受漏洞影响内存块的分配与释放时机。
- 使用一个指定值,覆盖紧邻受漏洞影响内存块之后的那个内存块的
POOL_HEADER(池头)结构体的前 4 个字节。
此外,受漏洞影响的内存块被分配在分页池(PagedPool)中。这一点至关重要,因为内存池的类型可能会影响漏洞利用过程中所选用的对象类型,进而对整个漏洞利用过程产生重大影响。不过,针对非分页池(NonPagedPoolNx)的漏洞利用手法与此非常相似,唯一的区别在于:在进行堆喷射(spraying)以及实现任意读操作时,它使用的是 PipeQueueEntry 对象,而非 PipeAttribute 对象。
在本示例中,我们选定的受漏洞影响内存块的大小为 0x180 字节。关于受漏洞影响内存块的大小选择及其对漏洞利用过程的影响,将在第 4.6 节中进行详细探讨。
创建“幽灵块”(Ghost Chunk)
此处的首要步骤是对堆内存进行“堆风水”(heap fengshui)布局,以便在受漏洞影响的内存块之后,紧接着放置一个由攻击者控制的对象。
被覆盖的内存块中存放的对象可以是任意类型,唯一的必要条件是攻击者必须能够控制该对象的释放时机。为了简化漏洞利用过程,最好选择一种支持进行“堆喷射”操作的对象类型(详见第 4.2 节)。
至此,即可触发该漏洞。被覆盖内存块的 POOL_HEADER 结构体将被替换为以下数值:
PreviousSize(前一内存块大小):0x15。该数值在内部计算时会被乘以 0x10。计算结果 0x180 - 0x150 = 0x30,即为伪造的 POOL_HEADER 结构体在受漏洞影响内存块内部的偏移量。
PoolIndex:0 或任意值,此参数未使用。
BlockSize:0 或任意值,此参数未使用。
PoolType : PoolType | 4. The CacheAligned bit is set.
必须在易受攻击的内存块(chunk)内,以一个已知偏移量的位置放置一个伪造的 POOL_HEADER。实现这一点的具体做法是:先释放该易受攻击的对象,随后利用一个 PipeAttribute 对象重新分配该内存块。
在此演示中,伪造的 POOL_HEADER 在该易受攻击内存块内的偏移量将被设定为 0x30。该伪造的 POOL_HEADER 具有如下形式:
PreviousSize:0,或任意值;该字段未被使用。
PoolIndex:0,或任意值;该字段未被使用。
BlockSize:0x21。该数值将乘以 0x10,从而确定被释放块(chunk)的大小。
PoolType:PoolType。其中的 CacheAligned 和 PoolQuota 位均未被设置。
选定的 BlockSize 并非随意选取,而是指实际将被释放的内存块(chunk)的大小。鉴于后续的目标是重用这块已分配的内存,因此必须选择一个易于重用的大小。由于所有小于 0x200 的大小均归属于 LFH(低碎片堆)管理范畴,故必须避开此类大小。不属于 LFH 管理的最小分配大小为 0x200,这对应于一个实际大小为 0x210 的内存块。大小为 0x210 的内存块采用 VS(可变大小)分配机制,并符合条件使用第 2.1 节中所述的“动态前瞻列表”(Dynamic Lookaside lists)。
通过大量分配并随后释放大小为 0x210 字节的内存块,即可激活针对该 0x210 大小的动态前瞻列表。
此时,此前已被覆盖的内存块可以被释放;这一操作将触发“缓存对齐”(cache alignment)机制。系统不再释放位于被覆盖内存块原始地址处的内存块,转而释放位于地址 OverwrittenChunkAddress - (0x15 * 0x10) 处的内存块——该地址同时也对应于 VulnerableChunkAddress + 0x30。此次释放操作所引用的 POOL_HEADER(内存池头)实际上是一个伪造的 POOL_HEADER;因此,内核并未释放那个存在漏洞的内存块,而是释放了一个大小为 0x210 的内存块,并将其置于动态前瞻列表的顶部。这一过程如图 23 所示。
遗憾的是,伪造的 POOL_HEADER 中所指定的 PoolType(内存池类型)字段,并不能决定被释放的内存块究竟是归入 PagedPool(分页内存池)还是 NonPagedPoolNx(不可分页内存池)。
动态查找列表(Dynamic Lookaside list)是根据分配块所属的段来选取的,而该段信息则源自于分配块(chunk)的地址。这意味着,如果存在漏洞的分配块位于分页池(Paged Pool)中,那么这个“幽灵”分配块也将被置入分页池对应的查找列表中。
此时,那个已被覆盖的分配块处于一种“丢失”状态:内核误以为它已被释放,且所有指向该分配块的引用均已被移除。因此,它将不再会被使用。
泄露“幽灵块”(Ghost Chunk)的内容
现在,该幽灵块可以被重新分配,并关联一个 PipeAttribute 对象。这个 PipeAttribute 结构体将覆盖位于易受攻击块(Vulnerable Chunk)中的属性值。通过读取该管道属性的值,即可读取相应数据,从而泄露出幽灵块中 PipeAttribute 的具体内容。至此,幽灵块的地址——进而也是易受攻击块的地址——便已为人所知。这一步骤如图 24 所示。
实现任意地址读取
易受攻击块可以被再次释放,并重新分配以关联另一个 PipeAttribute 对象。这一次,新分配的 PipeAttribute 数据将覆盖幽灵块中原有的 PipeAttribute。因此,幽灵块中的 PipeAttribute 现在已完全处于攻击者的掌控之下。一个新的 PipeAttribute 对象被注入到位于用户空间的链表中。这一步骤如图 25 所示。
此时,若请求读取幽灵块中 PipeAttribute 对象的属性值,内核实际上将引用位于用户空间——即完全受控——的那个 PipeAttribute 对象。正如前文所述,通过控制 AttributeValue 指针及 AttributeValueSize 字段,我们便获得了一个“任意地址读取”的基本原语(Primitive)。图 26 演示了这一任意地址读取的过程。
利用首次指针泄露和任意读取能力,可以获取指向 npfs 模块代码段(text section)的一个指针。通过读取导入表,可以进一步读取指向 ntoskrnl 模块代码段的指针,从而确定内核的基地址。在此基础上,攻击者能够读取 ExpPoolQuotaCookie 的数值,并获取当前利用进程对应的 EPROCESS 结构体地址及其 TOKEN 地址。
实现任意递减操作:首先,攻击者在内核空间内利用 PipeQueueEntry 伪造(craft)一个虚假的 EPROCESS 结构体;随后,利用任意读取能力获取该结构体的地址。
随后,该漏洞利用程序可以再次释放并重新分配那个存在漏洞的内存块(chunk),从而修改“幽灵块”(ghost chunk)及其关联的 POOL_HEADER 结构的内容。
该幽灵块的 POOL_HEADER 会被覆写为以下数值:
PreviousSize:0(或任意值),该字段在此处未被使用。PoolIndex:0(或任意值),该字段在此处未被使用。BlockSize:0x21。该数值随后会被乘以 0x10。PoolType:8。这意味着PoolQuota位已被置位。PoolQuota:ExpPoolQuotaCookieXORFakeEprocessAddressXORGhostChunkAddress
当该幽灵块被释放时,内核会尝试解引用(dereference)与其关联的 EPROCESS 结构中的配额计数器(Quota counter)。此时,内核将利用伪造的 EPROCESS 结构来定位并获取待解引用的数值指针。
这一过程提供了一种“任意递减”的基本操作原语。递减的数值即为 PoolHeader 中的 BlockSize 字段值;因此,该数值总是 0x10 的倍数,且其取值范围介于 0 到 0xff0 之间。
从“任意递减”到获取 SYSTEM 权限
2012 年,Cesar Cerrudo [3] 描述了一种通过修改 TOKEN 结构体中的 Privileges.Enabled 字段来提升权限的技术。Privileges.Enabled 字段用于记录当前进程已启用的特权列表。默认情况下,处于“低完整性级别”(Low Integrity Level)的令牌(Token)其 Privileges.Enabled 字段值通常为 0x0000000000800000,该数值仅启用了 SeChangeNotifyPrivilege(更改通知特权)。若对该位字段执行减一操作,其数值将变为 0x000000000007ffff,从而启用更多的特权。
具体而言,通过将该位字段的第 20 位(bit 20)置位,即可启用 SeDebugPrivilege(调试特权)。SeDebugPrivilege 允许进程调试系统中的任意其他进程,从而赋予了该进程向任何高权限进程注入代码的能力。
[1]中所详述的漏洞利用程序展示了一种名为“配额指针进程覆写”(Quota Pointer Process Overwrite)的技术;该技术正是利用上述的“任意递减”原语,来为当前进程启用 SeDebugPrivilege。图 27 形象地展示了这一技术实现过程。
然而,自 Windows 10 v1607 版本起,内核现在也会检查 Token(令牌)中 Privileges.Present 字段的值。Token 中的 Privileges.Present 字段列出了那些可以通过调用 AdjustTokenPrivileges API 为该 Token 启用(enable)的特权。因此,该 Token 实际拥有的特权现在由 Privileges.Present 与 Privileges.Enabled 进行按位与(&)运算后的结果位域决定。
默认情况下,处于“低完整性级别”(Low Integrity Level)的 Token,其 Privileges.Present 字段值被设置为 0x602880000。由于 0x602880000 & (1 << 20) == 0,仅仅在 Privileges.Enabled 字段中设置 SeDebugPrivilege 标志,并不足以真正获取到 SeDebugPrivilege 特权。
一种思路是尝试对 Privileges.Present 位域进行减量操作(decrement),从而将 SeDebugPrivilege 特权包含进 Privileges.Present 位域中。随后,攻击者便可调用 AdjustTokenPrivileges API 来启用 SeDebugPrivilege。然而,SepAdjustPrivileges 函数会执行额外的检查;根据 Token 完整性级别的不同,某些进程可能无法启用任何特权——即便所需的特权确实已存在于 Privileges.Present 位域之中。具体而言:对于“高完整性级别”(High Integrity Level),进程可以启用 Privileges.Present 位域中的任何特权;对于“中完整性级别”(Medium Integrity Level),进程仅能启用那些既存在于 Privileges.Present 中、又存在于特定位域 0x1120160684 中的特权;而对于“低完整性级别”(Low Integrity Level),进程仅能启用那些既存在于 Privileges.Present 中、又存在于特定位域 0x202800000 中的特权。
这意味着,那种仅凭一次任意地址减量操作便直接获取 SYSTEM 权限的技术,如今已不再奏效。
不过,若通过两次任意地址减量操作,这一目标依然可以完美达成:即先对 Privileges.Enabled 字段进行减量操作,随后再对 Privileges.Present 字段进行减量操作。具体实现上,可以重新分配那个“幽灵块”(ghost chunk),并对其 POOL_HEADER(池头)进行第二次覆盖,从而实现第二次任意地址减量操作。
一旦获取了 SeDebugPrivilege 权限,该漏洞利用程序即可打开任意 SYSTEM 进程,并向其注入一段 shellcode,从而以 SYSTEM 权限弹出一个 shell。
4.6 关于所呈示漏洞利用的讨论
本文所展示的漏洞利用代码及存在漏洞的驱动程序,均可在 [2] 获取。该漏洞利用仅作为概念验证(Proof of Concept),仍有进一步改进的空间。
4.7 关于脆弱对象大小的探讨
根据易受攻击对象大小的不同,该漏洞利用程序可能会有不同的要求。
上述漏洞利用程序仅适用于大小至少为 0x130 的易受攻击块(chunk)。这是因为“幽灵块”(ghost chunk)的大小要求——它必须至少为 0x210。如果易受攻击块的大小小于 0x130,那么在分配幽灵块时,将会覆盖掉紧随该易受攻击块之后的那个块,从而在后续释放内存时引发崩溃。虽然这个问题是可以修复的,但此处将其留作读者的练习题。
处于 LFH(大小小于 0x200 的块)中的易受攻击对象,与处于 VS 段(大小大于 0x200 的块)中的易受攻击对象之间存在几处差异。主要区别在于,VS 块在其数据内容之前额外包含一个头部(header)。这意味着,若要控制 VS 段中紧邻的下一个块的 POOL_HEADER,至少需要执行 0x14 字节的堆溢出操作。这也意味着,当被覆盖的块随后被释放时,其内部的 _HEAP_VS_CHUNK_HEADER 必须已被修复妥当。此外,还需特别留意,切勿释放紧随被覆盖块之后的那两个“喷射块”(sprayed chunks);因为 VS 段的内存释放机制可能会读取被覆盖块的 VS 头部信息,并试图将这三个空闲块合并在一起。
最后,正如第 4.4 节所阐述的那样,针对 LFH 和 VS 段所采取的“堆整形”(heap massaging)技术存在显著差异。
5 结论
本文描述了自 Windows 10 19H1 更新以来,内存池(Pool)内部机制所处的状态。Segment Heap 已被引入内核,且其正常运行不再依赖于块(Chunk)元数据。然而,曾位于每个块起始处的旧版 POOL_HEADER 结构依然存在,但其用途已发生了变化。
我们演示了几种利用 Windows 内核中的堆溢出漏洞所能发起的攻击,这些攻击通过针对内存池特有的内部机制进行攻击来实现。
本文所演示的攻击利用手法具有通用性,可适用于任何能够提供哪怕是极小规模堆溢出能力的漏洞,并允许攻击者实现从“低完整性级别”(Low Integrity level)到 SYSTEM 权限的本地提权。
引用
5. Tarjei Mandt. Kernel Pool Exploitation on Windows 7. Blackhat DC, 2011.
6. Haroon Meer. Memory Corruption Attacks The (almost) Complete History. Blackhat USA, 2010.
7. Mark Vincent Yason. Windows 10 Segment Heap Internals. Blackhat US, 2016.